
Qwen3千呼万唤始出来AG百家乐到底是真是假,径直登顶世界最强开源模子。
4月29日凌晨,阿里巴巴开源新一代通义千问模子Qwen3(简称千问3),旗舰模子Qwen3-235B-A22B参数目仅为DeepSeek-R1的1/3,总参数目235B,激活仅需22B,本钱大幅着落,性能全面突出R1、OpenAI-o1等世界顶尖模子,登顶世界最强开源模子。
千问3预锻练数据量达36T,并在后锻练阶段多轮强化学习,将快想考模式和慢想考模式无缝整合,同期在推理、辅导效能、器具调用、多讲话才智等方面均大幅增强,创下所有这个词国产模子及世界开源模子的性能新高。
千问3谋略八款模子,包含2款30B、235B的MoE模子,以及0.6B、1.7B、4B、8B、14B、32B等6款密集模子,每款模子均斩获同尺寸开源模子SOTA(最好性能)。
其中,千问3的30B参数MoE模子完毕了10倍以上的模子性能杠杆普及,仅激活3B就能比好意思上代Qwen2.5-32B模子性能;千问3的粘稠模子性能连续冲突,一半的参数目可完毕相通的高性能,如32B版块的千问3模子可跨级突出Qwen2.5-72B性能。
4月是大模子聚合发布的一月,OpenAI发布了GPT-4.1o3、o4mini系列模子,谷歌Gemini2.5FlashPreview夹杂推理模子上新,豆包也公布了1.5·深度想考模子,其他大模子厂商也开源或者更新了不少模子,业内也传出DeepSeekR2模子行将发布的音书,但当今大部分音书都是系风捕景。
无论DeepSeekR2发布与否,“后发制东说念主”的千问3,先一步站在大模子“难民化”的实在首先上。
国内首个夹杂推遐想考模子,增强Agent才智且维持MCP
千问3模子维持两种想考模式:
慢想考模式:在这种模式下,模子会徐徐推理,经过三想此后行后给出最终谜底。这种措施相等妥贴需要长远想考的复杂问题。
快想考模式:在此模式中,模子提供快速、近乎即时的反应,适用于那些对速率要求高于深度的浅薄问题。
所有这个词千问3模子都是夹杂推理模子,这也使其成为国内首个“夹杂推理模子”,“快想考”与“慢想考”集成进统一个模子,对浅薄需求可低算力“秒回”谜底,对复杂问题可多纰谬“深度想考”,大大从简算力浪掷。
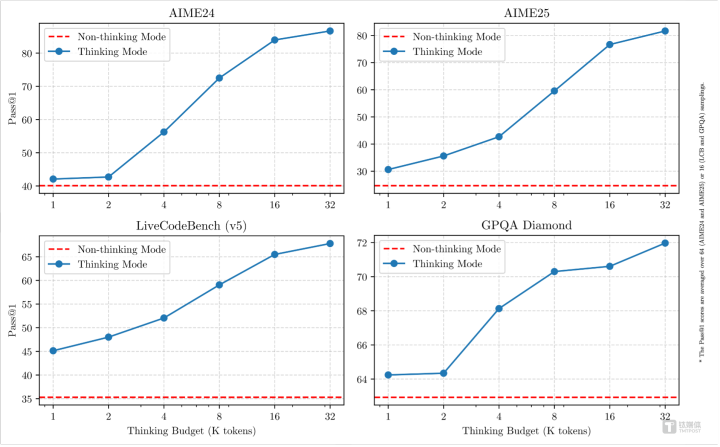
API可按需缔造“想考预算”(即预期最大深度想考的tokens数目),进行不同进度的想考,生动舒服AI应用和不同场景对性能和本钱的种种需求。比如,4B模子是手机端的绝佳尺寸;8B可在电脑和汽车端侧丝滑部署应用;32B最受企业大范畴部署宽待,有条目的拓荒者也可闲逸上手。
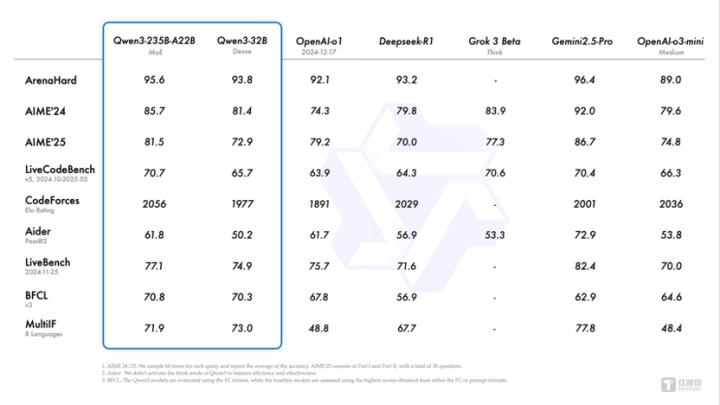
在奥数水平的AIME25测评中,千问3斩获81.5分,刷新开源记载;在老到代码才智的LiveCodeBench评测中,千问3冲突70分大关,发达以至跨越Grok3;在评估模子东说念主类偏好对王人的ArenaHard测评中,千问3以95.6分突出OpenAI-o1及DeepSeek-R1。
性能大幅普及的同期,ag百家乐解密千问3的部署本钱还大幅着落,仅需4张H20即可部署千问3满血版,显存占用仅为性能控制模子的三分之一。
千问3模子还维持119种讲话和方言。当今这些模子均在Apache2.0许可下开源,现已在HuggingFace、ModelScope和Kaggle等平台上怒放使用。
阿里巴巴也推选使用SGLang和vLLM等框架部署,而关于土产货使用,Ollama、LMStudio、MLX、llama.cpp和KTransformers等器具也维持。
千问3也计划了智能体Agent和大模子应用落地。在评估模子Agent才智的BFCL评测中,千问3创下70.8的新高,突出Gemini2.5-Pro、OpenAI-o1等顶尖模子,将大幅裁减Agent调用器具的门槛。
同期,千问3原生维持MCP合同,并具备刚毅的器具调用(functioncalling)才智,集结封装了器具调用模板和器具调用领会器的Qwen-Agent框架,将大大裁减编码复杂性,完毕高效的手机及电脑Agent操作等任务。
36万亿token预锻练,四阶段后锻练
在预锻练方面,Qwen3的数据集比较Qwen2.5有了权臣推广。Qwen2.5是在18万亿个token上进行预锻练的,而Qwen3使用的数据量果然是其两倍,达到了约36万亿个token。
为了构建这个普遍的数据集,千问团队不仅从蚁集上网罗数据,还从PDF文档中索求信息。举例使用Qwen2.5-VL从这些文档中索求文本,并用Qwen2.5立异索求履行的质地。
为了加多数学和代码数据的数目,千问团队愚弄Qwen2.5-Math和Qwen2.5-Coder这两个数学和代码规模的大家模子合成数据,合成了包括教科书、问答对以及代码片断等多种形态的数据。
预锻练过程分为三个阶段。在第一阶段(S1),模子在跨越30万亿个token上进行了预锻练,荆棘文长度为4Ktoken。这一阶段为模子提供了基本的讲话技术和通用常识。
在第二阶段(S2),千问团队通过加多常识密集型数据(如STEM、编程和推理任务)的比例来立异数据集,随后模子又在迥殊的5万亿个token上进行了预锻练。
在临了阶段,千问团队使用高质地的长荆棘文数据将荆棘文长度推广到32Ktoken,确保模子简略灵验地搞定更长的输入。
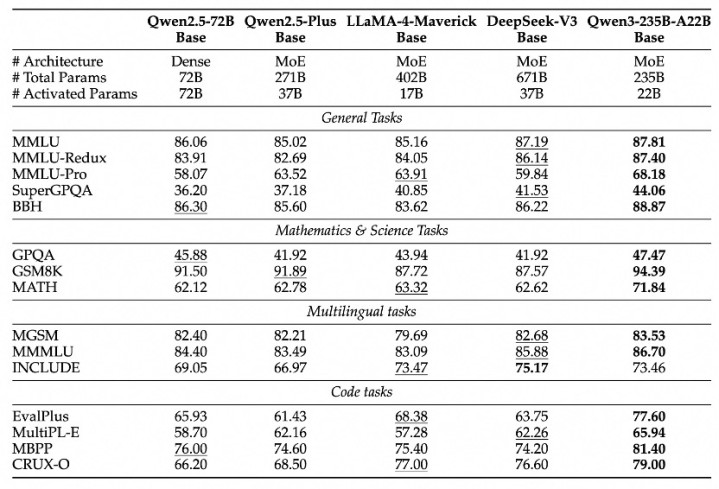
由于模子架构的立异、锻练数据的加多以及更灵验的锻练措施,Qwen3Dense基础模子的举座性能与参数更多的Qwen2.5基础模子特别。
举例,Qwen3-1.7B/4B/8B/14B/32B-Base折柳与Qwen2.5-3B/7B/14B/32B/72B-Base发达特别。极端是在STEM、编码和推理等规模,Qwen3Dense基础模子的发达以至跨越了更大范畴的Qwen2.5模子。
关于Qwen3MoE基础模子,它们在仅使用10%激活参数的情况下达到了与Qwen2.5Dense基础模子相似的性能。这带来了锻练和推理本钱的权臣从简。
后锻练方面,为了拓荒简略同期具备想考推理和快速反应才智的夹杂模子,千问团队实践了一个四阶段的锻练经由。该经由包括:(1)长想维链冷开首,(2)长想维链强化学习,(3)想维模式和会,以及(4)通用强化学习。
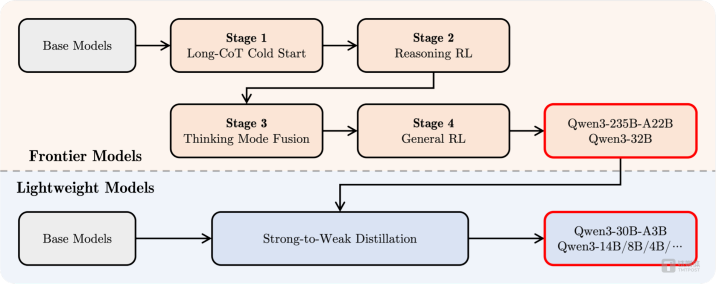
在第一阶段,先使用种种的的长想维链数据对模子进行了微调,涵盖了数学、代码、逻辑推理和STEM问题等多种任务和规模。这一过程旨在为模子配备基本的推理才智。
第二阶段的要点是大范畴强化学习,愚弄基于次第的奖励来增强模子的探索和钻研才智。
在第三阶段,在一份包括长想维链数据和常用的辅导微调数据的组合数据上对模子进行微调,将非想考模式整合到想考模子中,确保了推理和快速反应才智的无缝集结。
在第四阶段,在包括辅导效能、形态效能和Agent才智等在内的20多个通用规模的任务上应用了强化学习AG百家乐到底是真是假,以进一步增强模子的通用才智并改良不良举止。
