发布日期:2025-01-02 09:11 点击次数:159
 ag竞咪百家乐
ag竞咪百家乐
(起首:MIT Technology Review)
东说念主工智能离不开数据。为了检修算法以兑现预期规画,咱们需要盛大的数据,而输入到 AI 模子中的数据质地平直决定了输出恶果的优劣。相干词,问题在于 AI 诞生者和商议东说念主员对所使用的数据起首了解甚少。比较于 AI 模子诞生的复杂性,AI 的数据鸠合试验尚不练习,大界限数据集继续贫困对于其内容和起首的持重信息。
为了处理这一问题,来自学术界和产业界的 50 多名商议东说念主员开展了数据溯源规画(Data Provenance Initiative)。他们建议了一个肤浅而进犯的问题:构建 AI 所需的数据究竟来自那里?为此,他们审查了近 4,000 个全球数据集,这些数据集涵盖了 600 多种话语、67 个国度,并包含长达 30 年的数据,数据起首波及 800 个私有的渠说念和近 700 个组织。
这项商议的恶果初次独家发布在《麻省理工科技褒贬》上(文末附通告运动),揭示了一个令东说念主担忧的趋势:AI 的数据试验正在使职权过度集结于少数几家主导科技公司手中。
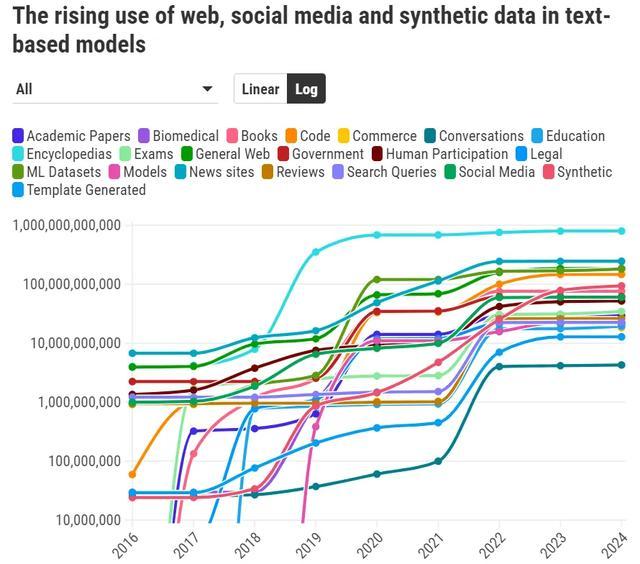
技俩成员、MIT 商议员 Shayne Longpre 默示,在 2010 年代初期,数据集的起首相对种种化。
(起首:MIT Technology Review)
这些数据不仅来自百科全书和互联网,还包括议会纪录、财报电话会议以及天气通告等起首。Longpre 指出,在阿谁时间,AI 数据集是凭证具体任务的需求全心操办并从不同渠说念鸠合的。
相干词,2017 年,撑持空话语模子的架构——Transformer 的出现,变嫌了这一切。跟着模子和数据集界限的不停扩大,AI 的性能权贵普及。这使得 AI 界限冉冉倾向于吸收更大界限的数据集。
如今,大多数 AI 数据集是通过从互联网上大界限、无离别地持取内容构建的。自 2018 年起,互联网成为通盘媒体类型(如音频、图像和视频)数据集的主要起首。与此同期,鸠合持取的数据与更为全心操办的数据集之间的差距冉冉露出并不停扩大。
(起首:MIT Technology Review)
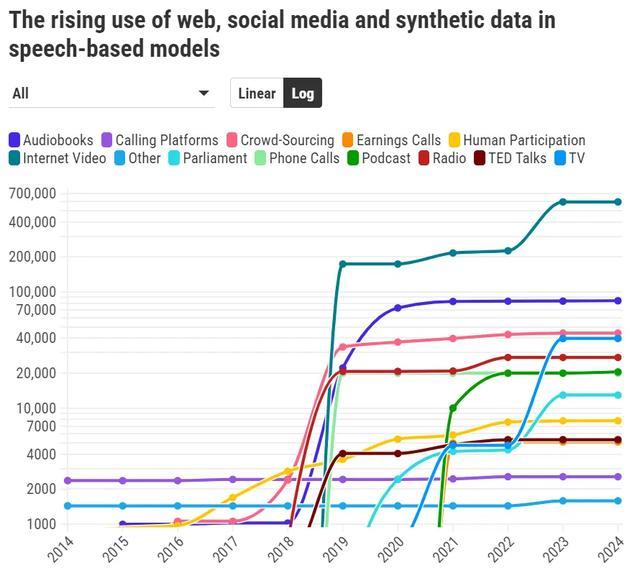
“在基础模子的诞生中,数据的界限、异质性以及鸠合起首对模子才调的影响无与伦比。”Longpre 默示。对数据界限的需求也极地面鼓励了合成数据的平时使用。
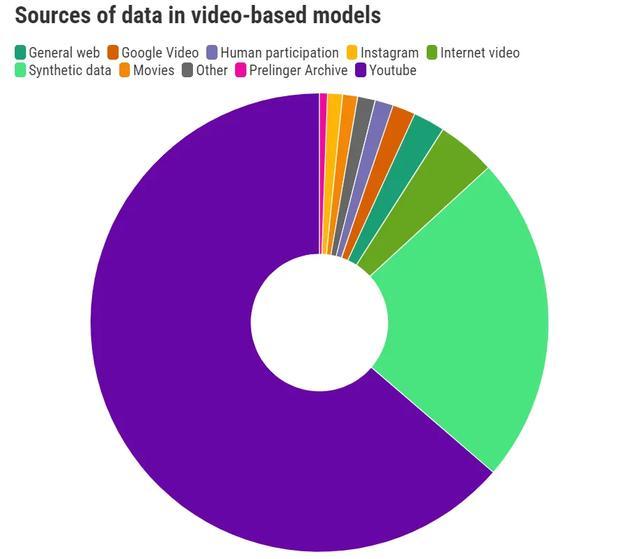
频年来,多模态生成式 AI 模子应时而生,这些模子简略生成视频和图像。与大型话语模子访佛,它们需要尽可能多的数据,而当今最优的数据起首是 YouTube。
以视频模子为例,从图表中不错看出,超 70% 的语音和图像数据集的数据齐来自合并起首。
(起首:MIT Technology Review)
对 YouTube、Google 的母公司 Alphabet 来说,这可能是一个宏大的上风。与文本数据散布在广大不同的网站和平台上不同,视频数据高度集结在单一平台。
Longpre 指出:“这使得鸠合上一些最进犯的数据的适度权高度集结在一家企业手中。”
此外,Google 本身也在诞生我方的 AI 模子,这种宏大的上风激发了对于公司怎么向竞争敌手提供这些数据的疑问。AI Now Institute 的集结推行主任 Sarah Myers West 默示,这值得进一步探讨。
她合计,ag百家乐网址“咱们应该将数据视为通过特定历程创造出来的东西,而不是一种当然存在的资源。”
她补充说念:“若是咱们日常使用的大部分 AI 所依赖的数据集响应的是大公司、以利润为导向的企业的意图和瞎想,那么这将以妥当这些大企业利益的花样重塑咱们的寰宇基础门径。”
这种单一化也激发了对于数据集是否简略准确响应东说念主类体验以及咱们正在构建何种模子的疑问。
Cohere 公司的商议副总裁、Data Provenance Initiative 成员 Sara Hooker 默示,“东说念主们上传到 YouTube 的视频继续是针对特定受众而制作的,视频中的举止频频带有特定的见解性。”她问说念:“这些数据是否捕捉到了东说念主类存在的通盘细小离别和种种性?”

粉饰的收尾
AI 公司继续不会公开用于检修模子的数据起首。一方面,这是为了保护其竞争上风;另一方面,由于数据集的打包和分发历程复杂且不透明,AI 公司本身也可能无法透顶了解所罕有据的具体起首。
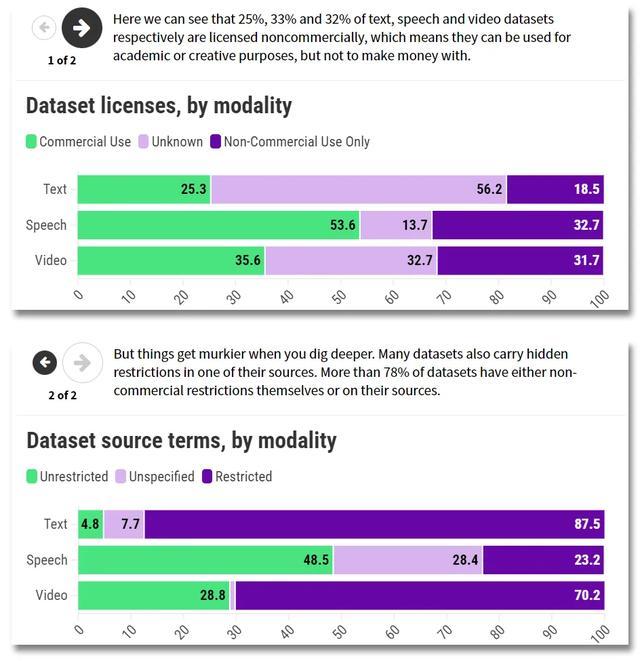
此外,AI 公司可能不了解这些数据在使用或分享时所受到的收尾。Data Provenance Initiative 的商议东说念主员发现,好多数据集附带有严格的许可要求或使用条件,例如,可能收尾其在生意用途上的欺骗。
(起首:MIT Technology Review)
“数据起首贫困一致性,使得诞生者很难正确采选使用的数据。”Hooker 默示。
Longpre 补充说念,这也让诞生者险些不可能透顶确保他们的模子莫得使用受版权保护的数据进行检修。
频年来,像 OpenAI 和 Google 这么的公司与出书商、Reddit 等主要论坛以及搪塞媒体平台达成了独派系据分享条约。这种作念法进一步自在了它们的职权。
“这些独家合同内容上将互联网离别为谁能访谒和谁不成访谒的不同区域。”Longpre 指出。
这种趋势对简略背负此类条约的大型 AI 公司故意,但对商议东说念主员、非渔利组织和袖珍公司则组成了不利。这些较小的参与者将难以赢得必要的数据,而大型公司不仅能坚毅独家条约,还领有最苍劲的资源用于持取数据集。
“这是咱们在洞开鸠合向前所未见的新一波非对称性访谒。”Longpre 说说念。

西方与其他地区的差距
用于检修 AI 模子的数据也存在严重的地域偏倚。商议东说念主员分析发现,迥殊 90% 的数据集来自欧洲和北好意思,而来自非洲的数据不及 4%。
Hooker 指出:“这些数据集仅响应了咱们寰宇和文化的一部分,却透顶冷落了其他地区。”
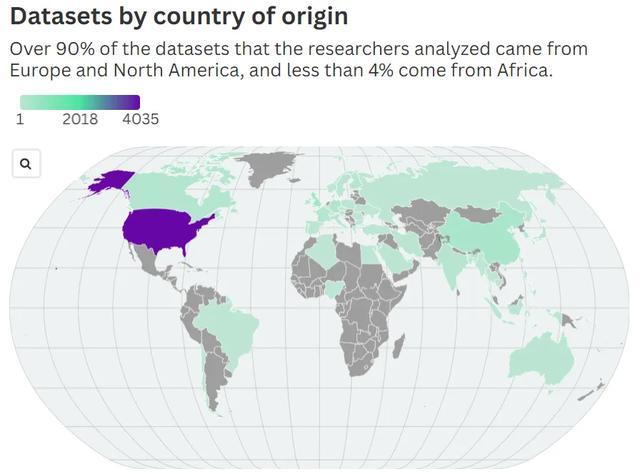
(起首:MIT Technology Review)
用于检修 AI 模子的数据也存在严重的地域偏倚。商议东说念主员分析发现,迥殊 90% 的数据集来自欧洲和北好意思,而来自非洲的数据不及 4%。
Hooker 指出:“这些数据集仅响应了咱们寰宇和文化的一部分,却透顶忽略了其他部分。”
检修数据中英语的主导地位部分不错用互联网的近况来阐扬。Hugging Face 的首席伦理学家 Giada Pistilli(并未参与这次商议)默示,互联网上迥殊 90% 的内容仍然是英语,而地球上好多地区的互联网勾通终点差,致使莫得互联网。不外,她补充说,另一个原因是便利性:创建其他话语的数据集并将其他文化纳入考虑需要有坚硬的规画和盛大的职责。
这种数据集的西方倾向在多模态模子中发扬得尤为彰着。Hooker 例如说,当一个 AI 模子被辅导生授室典的场景和声息时,它可能只可呈现出西方婚典的神色,因为它的检修数据仅限于此。
这种情况强化了偏见,可能导致 AI 模子鼓励一种以好意思国为中心的寰宇不雅,从而灭亡其他话语和文化的存在。
Hooker 指出:“咱们在全球范围内使用这些模子ag竞咪百家乐,但模子所能看见的寰宇与看不见的寰宇之间存在宏大差距。”