IT之家2月23日音问AG百家乐有没有追杀,本周,OpenAI的又名职工公开训斥埃隆・马斯克旗下的xAI公司,称其发布的最新AI模子Grok3的基准测试成果具有误导性。对此,xAI的都集首创东谈主伊戈尔・巴布什金(IgorBabushkin)则坚称公司并无不当。
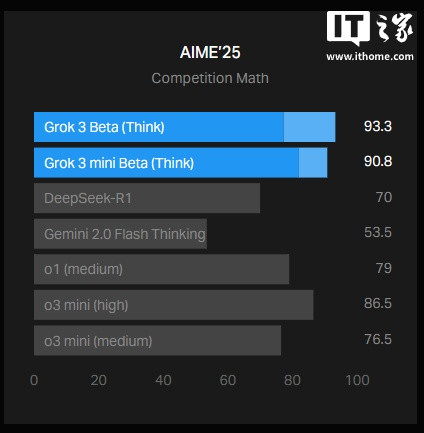
xAI在其博客上发布了一张图表,展示了Grok3在AIME2025(一项近期邀请制数学磨练中的高难度数学题集)上的推崇。尽管一些行家质疑AIME四肢AI基准的有用性,但AIME2025特别早期版块仍被粗犷用于评估模子的数学智商。
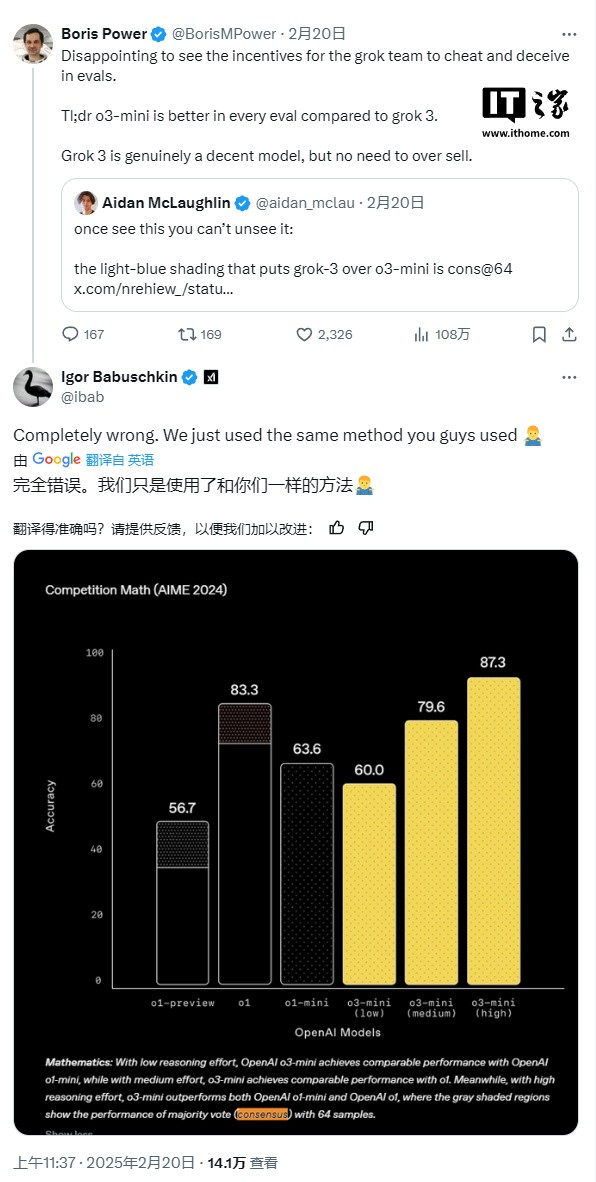
IT之家谛视到,xAI的图表示馅,Grok3的两个版块——Grok3ReasoningBeta和Grok3miniReasoning——在AIME2025上的推崇开首了OpenAI现时最强的可用模子o3-mini-high。然则,OpenAI的职工很快在X平台上指出,xAI的图表并未包含o3-mini-high在“cons@64”条目下的AIME2025得分。
“cons@64”是指“consensus@64”,即允许模子在基准测试中对每个问题尝试64次,网络彩票和AG百家乐并将出现频率最高的谜底四肢最终谜底。可思而知,这种花式往往会显赫普及模子的基准测试分数,若是图表中不详这一数据,就可能让东谈主误合计某个模子的推崇优于另一模子,而实质情况偶而如斯。
在AIME2025的“@1”条目下(即模子初度尝试的得分),Grok3ReasoningBeta和Grok3miniReasoning的得分低于o3-mini-high。Grok3ReasoningBeta的推崇也略低于OpenAI的o1模子在“中等计较”缔造下的得分。然则,xAI仍在宣传Grok3为“天下上最贤慧的AI”。
巴布什金在X平台上辩称,OpenAI往日曾经发布过近似的误导性基准测试图表。尽管这些图表是用于相比其自己模子的推崇。
在这场争议中,一位中立的第三方再行绘图了一张更为“准确”的图表:
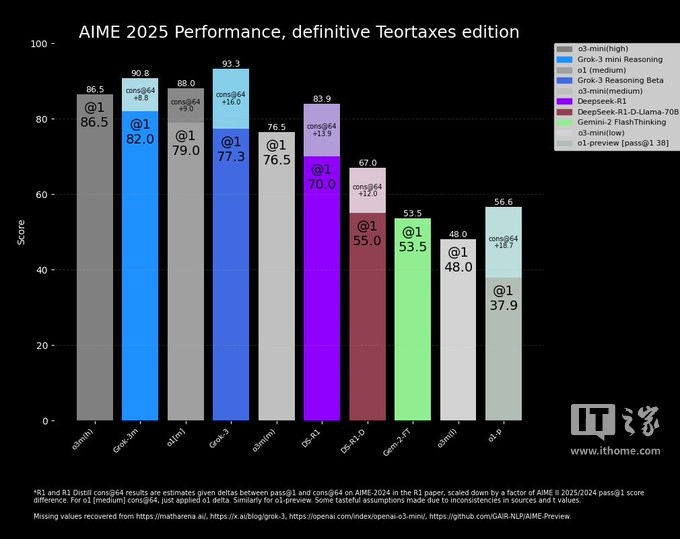
但正如AI磋磨员内森・兰伯特(NathanLambert)在一篇著作中指出的AG百家乐有没有追杀,八成最热切的概念仍然未知:每个模子达到最好分数所需的计较(和钞票)资本。这碰巧标明,大多半AI基准测试在传达模子的局限性和上风方面仍然存在很大的不及。