
ag百家乐交流平台 DeepSeek-R1下载量超1000万次, 成最受宽饶开源大模子!

今天凌晨2点,公共最灵通源平台Hugging Face聚合独创东谈主Clément Delangue晓喻——DeepSeek R1 在发布只是几周后,就成为了Hugging Face 平台上有史以来最受宽饶的模子。
咫尺已罕有千个魔改造体模子,下载量进步了1000万次!

开源地址:https://huggingface.co/deepseek-ai/DeepSeek-R1
凭证DeepSeek-R1在Hugging Face上的数据自大,上个月的下载量是370万次。在公共火爆出圈之后,揣测这个月保底800万次以上。
咫尺打开Hugging Face,基于阿里开源的Qwen系列魔改造体R1模子相等多,这属于是国潮强强聚合啦。


网友示意,他最少就孝顺了50次,但以后还会更多。

开源AI模子有着光明的改日!

令东谈主印象深远额配置,祝愿相关团队;AGI要完结了!
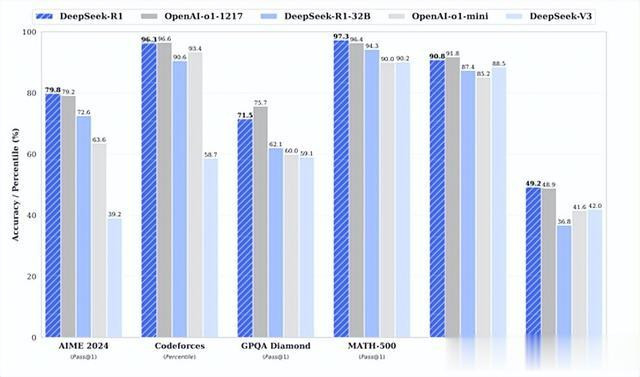
DeepSeek在上个月发布了R1版块,在好意思国AIME 2024测试中R1拿下79.8分,进步了OpenAI的o1模子的79.2分;在MATH-500,R1为97.3分,雷同进步了o1的96.4分;
在SWE-bench Verified,R1为49.2分再次进步了o1的48.9分。而在代码测试Codeforces中,R1仅比o1模子低0.3分;MMLU低1分;GPQA低4.2分,举座性能与o1模子很是。
但价钱方面o1模子每100万tokens的输入是15好意思元,R1是0.14好意思元,比GPT-4o-mini价钱还要低资本猛降90%。
输出价钱则更是低的离谱,o1每100万tokens输出是60好意思元,R1惟一2.19好意思元,裁减了27倍傍边。
在DeepSeek晓喻开源R1后,飞快在公共规模走红,还对好意思国科技股形成重创一直火爆于今。
R1通俗先容
其实DeepSeek最脱手建设的是R1-Zero模子,通过纯强化学习视察,不依赖于任何监督学习数据。该模子以DeepSeek-V3-Base为基础,选拔了GRPO算法进行视察,通过采样一组输出并盘算其相对上风,从而优化模子的政策,幸免了传统强化学习中需要与政策模子同范畴的评估模子,大大裁减了视察资本。
在视察过程中,R1-Zero展现出了一系列刚劲的推理行径,举例,自我考据、反念念和生成长推理链等。这些行径并非东谈主为植入,而是模子在强化学习过程中天然走漏的扬弃。举例,在AIME 2024数学竞赛中,R1-Zero的Pass@1得分从开动的15.6%擢升至71.0%,通过多数投票进一步擢升至86.7%,与OpenAI-o1-0912模子很是。这一扬弃阐述了纯强化学习在擢升模子推理身手方面的重大后劲。
然而R1-Zero也存在一些问题,如可读性差和话语混用等。是以,DeepSeek又建设出了R1模子。
R1在R1-Zero的基础上进行了更正,ag百家乐真实性引入了冷启动数据和多阶段视察经由,以擢升模子的推理身手和可读性。
冷启动与多阶段视察
冷启动阶段是R1视察经由的起始,亦然总共这个词视察政策中最蹙迫的一环。与R1-Zero胜仗从基础模子脱手强化学习不同,R1引入了小数高质料的长CoT数据动作冷启动数据,为模子提供一个愈加褂讪和优化的起始,从而在后续的强化学习过程中更好地发展推理身手。

冷启动数据的一个重要特色是其对可读性的优化。与R1-Zero生成的推理过程比拟,冷启动数据愈加冷静话语的显着性和逻辑性。举例,团队瞎想了一种特定的输出体式,即在每个回复的末尾添加一个回来,并用罕见秀雅将推理过程和回来折柳开来。
这种体式不仅使模子的输出愈加易于健硕,也为后续的强化学习提供了一个明确的结构框架。
在冷启动阶段之后, R1参预了一个包含多个阶段的复杂视察经由。这如故由的瞎想指标是通过徐徐优化和颐养,使模子在推理身手上达到更高的水平,同期在其他任务上也明白出色。
第一阶段:推理导向的强化学习
在冷启动数据的基础上,R1参预了一个以推理为导向的强化学习阶段。这一阶段的中枢指标是通过大范畴的强化学习,进一步擢升模子在数学、编程、科学和逻辑推理等任务上的明白。这一阶段的视察与R1-Zero的强化学习过程访佛,但有一个蹙迫的区别:R1在视察过程中引入了话语一致性奖励。
话语一致性奖励的引入是为了贬责模子在生成推理链时可能出现的话语混用问题。在多话语的推理任务中,模子可能会在推理过程中混用不同话语,这不仅影响了输出的可读性,还可颖悟扰模子的推理逻辑。
为了克服这一问题,相关团队瞎想了一个奖励机制,通过盘算推理链中指标话语的比例来优化模子的输出。天然这种奖励机制在一定进程上稍许裁减了模子的推感性能,但它权臣擢升了输出的可读性和一致性。
第二阶段:圮绝采样与监督微调
当推理导向的强化学习接近拘谨时,R1参预了一个重要的阶段:圮绝采样与监督微调。这一阶段的指标是通过生成新的监督学习数据,进一步优化模子在推理和其他任务上的明白。
圮绝采样是一种从模子生成的数据中筛选出高质料样本的设施。在这一阶段,相关团队运用刻下模子的视察点,通过圮绝采样生成了无数的推理相关数据。这些数据不仅包括了推理任务的样本,还涵盖了写稿、事实问答、自我明白等其他规模的数据。通过这种相貌,模子不仅在推理任务上取得了优化,还在其他任务上展现了更强的身手。
第三阶段:全场景强化学习
在经过圮绝采样和监督微调之后,R1参预了一个更为复杂的阶段:全场景强化学习。这一阶段的指标是通过蛊惑推理任务的章程奖励和一般任务的偏好奖励,进一步优化模子的性能。
在这一阶段,模子不仅需要在推理任务上明白出色,还需要在其他任务上展现出更高的灵验性和安全性。相关团队通过引入种种化的奖励信号和任务散布,确保模子在推理身手、灵验性和安全性之间达到均衡。这不仅擢升了模子在推理任务上的明白,还使其在其他任务上也展现出了更强的符合性。
举例,在推理任务中ag百家乐交流平台,模子不息使用章程奖励来优化其推理链的准确性和成果。而在一般任务中,模子则依赖于偏好奖励来优化其输出的灵验性和安全性。通过这种相貌,R1大要在多个任务上展现出超卓的性能,同期保握推理身手的中枢上风。