作家| 孙鹏越
裁剪|大 风
杭州AI通宵火了。
有网友捉弄谈,很有意想啊!咱们小小的杭州,干掉好意思国三大科技巨头。
一家名叫幻方量化(Deepseek)的AI公司,干出来拼多多式的大业,让全宇宙为之震撼,把AI教师资本成功打下来99%,突破了OpenAl的霸权; 一家名叫宇树(Unitree)的机器东谈主公司,干掉了好意思国最知名的工程与机器东谈主计算公司波士顿能源,秒杀正本的液压期间阶梯,反超波士顿能源的机器狗; 一家名叫毫微(Nano Labs)的无晶圆厂IC计算公司,刚刚推出FPU3.0 AI ASIC计算架构,同类家具已超英伟达的五倍以上。
在科技圈,一直流传着“AI四小龙”商汤、旷视、云从、依图科技;“大模子六小虎”智谱、MiniMax、月之暗面、百川、零一万物、阶跃星辰。
目下,杭州也有了我方的AI三守旧。
改变AI时期的底层逻辑
家喻户晓,AI大模子越智能,支捏的场景越多,就意味着它需要的芯片和算力就越多。
全宇宙的算力需求,让英伟达从一家显卡厂商,硬生生变嫌成一家三万亿好意思元市值的巨无霸。
但哪怕是英伟达、AMD、英特尔等沿路半导体公司加起来,也旺盛不了AI阛阓逐年上扬的算力需求。
就在统统AI公司齐苦于算力缺口之际,来自中国杭州的一家AI创企幻方量化,发布了一个参数目高达671B的大模子:DeepSeek-V3。
更让东谈主讶异的是,DeepSeek-V3只是只用了2048块GPU教师了2个月,且只破耗557.6万好意思元。
对比OpenAI的GPT-4o,它的教师资本约为1亿好意思元,至少在10000个GPU的谋略集群上教师。
也即是说,幻方量化只用了五分之一的芯片,二相当之一的资本,就教师出一个参数目第一梯队的大模子。
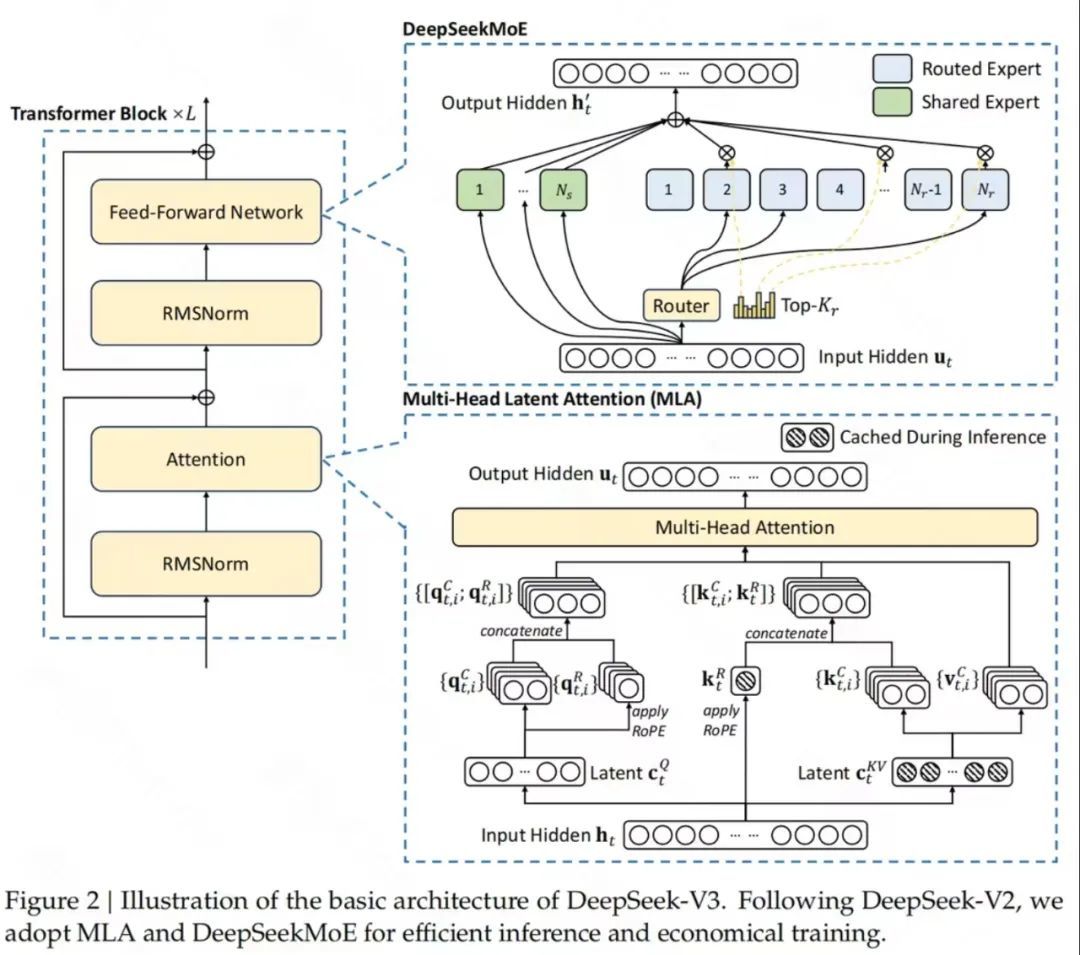
DeepSeekMoE
这么的获利瞬息引爆了统统这个词AI阛阓。
前OpenAI纠合首创东谈主、Tesla AI团队负责东谈主Andrej Karpathy在外交平台发文概叹谈:”Llama 3 405B使用了3080万GPU小时,而DeepSeek-V3看起来是一个更广泛的模子,仅使用了280万GPU小时(谋略量约为相当之一)。“
“如果DeepSeek-V3的优良浮现大致得回粗俗考据,这一模子将是在资源受限的情况下,在讨论和工程方面让东谈主印象深入的一次展示。”
据DeepSeek-V3研发团队示意,之是以能用较低的价钱完成高难度大模子教师,主若是接受了高效推理的多头潜在提防力(MLA)和用于经济教师的DeepSeekMoE。
多Token预测指标(Multi-Token Prediction,MTP)有益于提高模子性能,不错用于推理加快的臆度解码。并接受一种更动挨次,将推理才智从长想维链模子(DeepSeek R1)中,蒸馏到轨范模子上。
这种“散布式推理”的格式早有东谈主提议,举例OpenAI纠合首创东谈主兼前首席科学家Ilya Sutskever就也曾说过:“咱们照旧达到了数据峰值,AI预教师时期无疑将闭幕。”
但没料想的是,一直将中国大模子视为“低价替代品”的好意思国企业,在“散布式推理”范畴上,被一家中国杭州的企业先拔头筹,用期间给他们好好上了一课。
不错说,DeepSeek-V3让AI宇宙享受到了拼多多式的欢欣。

从机器东谈主到半导体计算
如果说DeepSeek-V3的出现,让硅谷巨头们澄澈意志到中国AI产业的卓绝速率,而宇树(Unitree)和毫微(Nano Labs)则络续让他们处于“捏续应激”之中。
前不久,宇树发布了旗下行业级机器狗B2-W(B2机器狗的进阶版)的炫技视频,在视频中,B2-W机器狗演示了若何爬山、涉水、越障,克服波折地形、触动路面解析行走。

宇树B2-W机器狗
除此以外,B2-W机器狗还能完成高难度的杂技动作:原地旋转稳停、两足倒立旋转、2.8米高楼飞跃。另外,百家乐ag厅投注限额该机器东谈主可负载40千克行走,一个成年男性的分量不在话下。
宇树B2-W机器狗视频激发了全网热议,就连太平洋此岸的马斯克,也忍不住转发并指摘颂扬。
B2-W机器狗不单是是一个“高价宠物”,它最适应的场景是专科范畴,比如安防巡检、勘探探索、环球赞助、医疗防疫陪护等危急厂家,让东谈主员幸免事故风险。
据新华社12月14日报谈,警用机器狗加入成齐市公安局高新分别局查看大队,开展安全查看和宣防责任。
值得一提的是,机械狗正本是好意思国高科企业的代表,就比如波士顿能源,从2005年就开始研发出第一款“大狗机器东谈主”。
彼时,宇树基本上只是波士顿能源的奴婢,随着大佬的脚步少量点“泥古不化”,从家具形态再到生意生态位,宇树一直走的是波士顿能源“平替版”阶梯。
联系词只是只过了数年时辰,宇树就得胜研发出解析性更高、均衡性更强的动轮决议,取代了波士顿能源的四足决议,一年时辰里完成了能在户外环境里航海梯山的教师。
不少波士顿能源的死忠粉纷繁破防,还认为宇树B2-W机器狗的视频一定是AI生成的CGI画面。

宇树B2-W机器狗
除了大模子和机器东谈主,在半导体范畴,也有一家杭州公司,对“巨东谈主”英伟达发起了冲锋。
那即是毫微(Nano Labs)。
12月26日,Nano Labs负责推出FPU3.0,接受ASIC架构,在能效上竣事了五倍的培植,建立了能源高效、高性能ASIC的新轨范。能粗俗欺诈于AI推理、边际AI谋略、5G数据传输解决和收罗加快等范畴。
行为AI与区块链期间的老玩家,Nano Labs是国内首先的无晶圆厂IC计算公司,从2022年就连接推出多款HTC和HPC芯片计算的全新基础构架芯片。
目下来说,ASIC架构芯片照旧成为AI宇宙的主流遴选。
在实行大限度特定的AI任务时,ASIC不错针对特定欺诈计算的芯片,进一步提高谋略的后果、裁减功耗并提高性能。
摩根士丹利在12月15日发布研报《AI ASIC 2.0:潜在赢家》认为ASIC凭借针对性优化和资本上风,有望缓缓从英伟达GPU手中争取更多阛阓份额。
预测AI ASIC阛阓限度将从2024年的120亿好意思元增长至2027年的300亿好意思元,年复合增长率达到34%。
目下,ASIC芯片一又友圈缓缓扩大,谷歌、Meta、微软、亚马逊等大厂齐将推出自家AI ASIC芯片。

为什么是杭州?
“中好意思贸易战里最大矛盾,是华盛顿市宾夕法尼亚大街1600号临时住户与深圳市南山区粤海街谈企业之间的纠纷。”
这是前几年最火热的段子,而“华盛顿市宾夕法尼亚大街1600号”是指好意思国白宫;
“深圳市南山区粤海街谈企业”则是指华为、大疆、中兴、腾讯等坐落在深圳南山区粤海街谈的中国科技大厂们。
如今中好意思贸易战热度裁减,科技战斗的矛盾点渐渐转变到了当下互联网的核心:AI。
相似, 和好意思国科技巨头的挣扎前哨,也从深圳南山区转变到杭州。
许多东谈主不知谈,早在AI海浪之前,杭州就照旧被称为东谈主工智能的“东方硅谷”,更是国内第一座“东谈主工智能之城”。

杭州城市大脑
2016年10月,杭州成为全宇宙第一个启动“城市大脑”基础扶植。
杭州将装配一个东谈主工智能核心:杭州城市数据大脑。让数据匡助城市来作念想考和决策,将杭州打形成一座大致自我调动、与东谈主类良性互动的城市。
好意思国驰名城市表面家、社会玄学家Lewis Mumford在著述《期间与时髦》中说起,东谈主类城市发展分红三个阶段:古希腊城市(运行时髦),中叶纪基督教城市(生意时髦),近代和当代工业城市(工业时髦)。
全宇宙第一个启动城市大脑的杭州,将对城市时髦发起第四次海浪,一个基于互联网、数据和东谈主工智能的“科技之城”。
如果你问我,为何是杭州?为何是他们?为何是本年?
那么这即是谜底凯时AG百家乐。